Introducing Verde
Verde is a Python library for processing spatial data (bathymetry, geophysics surveys, etc) and interpolating it on regular grids (i.e., gridding).
It implements Green’s functions
based interpolation methods and other data processing routines.
The type of gridding implemented in Verde is essentially fitting various linear models
to spatial data and using them to predict new data on regular grids, which is what a lot
of machine learning is all about.
So Verde’s gridder API
is inspired on scikit-learn, the state-of-the-art for
machine learning in Python.
The Green’s functions that make up the Jacobian matrix (aka sensitivity or feature
matrix) of the linear models generally come from elastic deformation theory.
For example, the bi-harmonic spline (Sandwell, 1987)
implemented in verde.Spline comes from the deformation of a thin elastic plate.
I submitted a paper about Verde to the Journal of Open Source Software (JOSS) where it’s currently awaiting review. This is my first time submitting to JOSS, though I have reviewed for it before. If you need academic credit for an open-source software project, I recommend giving JOSS a shot. Unlike many “geoscience computing” journals, you’ll actually get great feedback on your code and project structure.
Dig In
Verde comes with an example gallery,
tutorials, and
a range of sample datasets
to get you started (which are managed by Pooch under the
hood).
You can install it from PyPI using pip:
pip install verde
Conda packages will be available soon. We have a conda-forge feedstock ready and are just waiting on issue conda-forge/staged-recipes#6659.
The code is hosted on Github under the Fatiando a Terra organization: fatiando/verde.
Example
Here is an example code that interpolates our sample air temperature dataset:
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import pyproj
import numpy as np
import verde as vd
Verde is imported as vd in all our documentation. You can access all functions from
directly from the verde base package namespace.
## Load the air temperature data from Texas
data = vd.datasets.fetch_texas_wind()
coordinates = (data.longitude.values, data.latitude.values)
region = vd.get_region(coordinates)
## Use a Mercator projection for our Cartesian gridder
projection = pyproj.Proj(proj="merc", lat_ts=data.latitude.mean())
## The output grid spacing will 15 arc-minutes
spacing = 15 / 60
We can evaluate model performance by splitting the data into a training and testing set. We’ll use the training set to grid the data and the testing set to validate our spline model.
train, test = vd.train_test_split(
projection(*coordinates), data.air_temperature_c, random_state=0
)
Now we can chain a blocked mean and spline using verde.Chain to create a data
processing pipeline. The Spline can be regularized by setting the damping parameter.
It’s also a good idea to set the minimum distance to the average data spacing to avoid
singularities in the spline.
chain = vd.Chain(
[
("mean", vd.BlockReduce(np.mean, spacing=spacing * 111e3)),
("spline", vd.Spline(damping=1e-10, mindist=100e3)),
]
)
print(chain)
Chain(steps=[('mean', BlockReduce(adjust='spacing', center_coordinates=False,
reduction=<function mean at 0x7f5df74048c8>, region=None,
spacing=27750.0)), ('spline', Spline(damping=1e-10, engine='auto', force_coords=None, mindist=100000.0))])
Fit the model on the training set like you would with scikit-learn. And calculate an R² score coefficient on the testing set. The best possible score (perfect prediction) is 1. This can tell us how good our spline is at predicting data that was not in the input dataset.
chain.fit(*train)
score = chain.score(*test)
print("Score: {:.2f}".format(score))
Score: 0.86
Now we can create a geographic grid of air temperature by providing the projection
function to the grid method. The output of grid is an
xarray.Dataset that is ready to be plotted or saved to
netCDF.
grid_full = chain.grid(
region=region,
spacing=spacing,
projection=projection,
dims=["latitude", "longitude"],
data_names=["temperature"],
)
## Mask points that are too far away from the original data points.
grid = vd.distance_mask(
coordinates, maxdist=4 * spacing * 111e3, grid=grid_full, projection=projection
)
print(grid)
<xarray.Dataset>
Dimensions: (latitude: 43, longitude: 51)
Coordinates:
* longitude (longitude) float64 -106.4 -106.1 -105.9 -105.6 -105.4 ...
* latitude (latitude) float64 25.91 26.16 26.41 26.66 26.91 27.16 ...
Data variables:
temperature (latitude, longitude) float64 nan nan nan nan nan nan nan ...
Attributes:
metadata: Generated by Chain(steps=[('mean', BlockReduce(adjust='spacing...
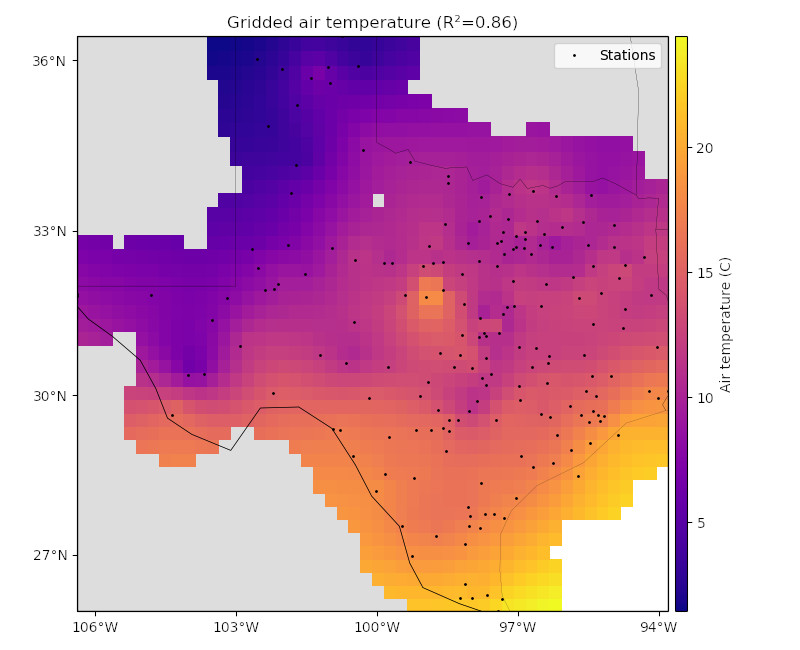
And finally, plot the grid and the original data points.
plt.figure(figsize=(8, 6.5))
crs = ccrs.PlateCarree()
ax = plt.axes(projection=ccrs.Mercator())
ax.set_title("Gridded air temperature (R²={:.2f})".format(score))
ax.plot(*coordinates, ".k", markersize=2, label="Stations", transform=crs)
tmp = ax.pcolormesh(
grid.longitude,
grid.latitude,
grid.temperature,
cmap="plasma",
transform=crs,
)
plt.colorbar(tmp, pad=0.01, aspect=50).set_label("Air temperature (C)")
ax.legend()
## Use an utility function to add tick labels and land and ocean features to the map.
vd.datasets.setup_texas_wind_map(ax, region=region)
plt.tight_layout()
plt.show()
Getting Involved
Verde is a part of my large-scale refactor of Fatiando a Terra and there is lot’s of room for improvement. The 1.0.0 release was focused on setting the look-and-feel of the library and getting the essential functionality in there. As it stands, Verde can already be used on moderately sized datasets, given that you have enough RAM. In fact, Verde is the engine behind my work on 3-component GPS interpolation.
The code is BSD licensed and we would love contributions of any form! You can browse the open issues on the Github repository to see if there is anything that you would like to work on. We welcome feature requests, bug reports, typo fixes, and examples.
If you’re new to open-source but want to give it a try, take a look at our Contributing Guide and the issues tagged with “good first issue”. We commit to help you get started and work through your first contributions.
If you give Verde a try, please let me know what you think. Any feedback would be greatly appreciated!